Sztuczna inteligencja mocno zakorzeniła się w różnych dziedzinach działalności, a nauka nie jest tu wyjątkiem. Wielu naukowców aktywnie wykorzystuje go w procesie pisania prac naukowych. Dlatego przed publikacją czasopisma naukowe dokładnie sprawdzają artykuły pod kątem śladów AI. Ale czy takie wykrywacze są naprawdę skuteczne? Czy dają stuprocentową gwarancję wiarygodności wyników? Dzisiaj porozmawiamy o tym bardziej szczegółowo.

Detektory sztucznej inteligencji: Czy działają skutecznie?
Przestrzeganie zasad uczciwości akademickiej jest podstawą działalności naukowej. Dlatego przed wysłaniem artykułu do recenzji czasopisma naukowe sprawdzają go pod kątem ewentualnych oznak wykorzystania sztucznej inteligencji. W tym celu istnieją specjalne narzędzia, które analizują tekst i dostarczają raport o jego unikalności. Jednak w praktyce takie wykrywacze AI nie działają bezbłędnie. Wręcz przeciwnie, mają wiele wad, które mogą znacząco wpłynąć na obiektywność wyników. Jak się one objawiają?
Wada 1: Fałszywie pozytywne wyniki z powodu stylu akademickiego
Teksty naukowe z natury mają podobny styl pisania, ponieważ używa się w nich ustalonych terminów, typowych konstrukcji zdań i neutralnego tonu. W trakcie analizy detektory poszukują właśnie tych cech, w szczególności powtarzających się szablonów językowych, formalnego stylu i jasnej struktury. Są to tak zwane „markery”, które mają świadczyć o tym, że autorem tekstu nie jest człowiek, a narzędzie oparte na sztucznej inteligencji.
W rezultacie powstaje paradoks: autor, który dobrze posługuje się stylem naukowym, używa prawidłowej terminologii i przestrzega standardów, automatycznie budzi podejrzenia. Im lepiej napisany jest artykuł, tym większe prawdopodobieństwo, że wykrywacz błędnie zidentyfikuje go jako tekst stworzony przez sztuczną inteligencję. W rezultacie daje on fałszywie pozytywne wyniki i wysoki odsetek wykorzystania sztucznej inteligencji.
Wada 2: Niezrozumienie, w jaki sposób autorzy faktycznie wykorzystują technologie AI
W środowisku naukowym panuje przekonanie, że badacze wykorzystują technologie sztucznej inteligencji wyłącznie do generowania pełnego tekstu artykułu. W rzeczywistości jest to jednak uprzedzenie, ponieważ współcześni naukowcy wykorzystują sztuczną inteligencję jako pomocnika na różnych etapach pracy, na przykład do generowania pomysłów podczas burzy mózgów, do strukturyzowania dużej ilości danych, do parafrazowania skomplikowanych sformułowań, do poprawiania gramatyki w tekstach w języku obcym lub do poprawiania czytelności poszczególnych akapitów. Jest to punktowe, świadome wykorzystanie narzędzia, w którym główne idee, metodologia i wnioski pozostają autorstwa autora.
Jednak detektory nie dostrzegają tej różnicy. Dla algorytmu nie ma znaczenia, czy cały artykuł został wygenerowany jednym zapytaniem, czy też model językowy został wykorzystany tylko do poprawienia dwóch zdań. Każde użycie technologii wspomagających automatycznie oznacza artykuł jako „napisany przez sztuczną inteligencję”, co nie odpowiada rzeczywistości.
Wada 3: Brak możliwości oceny rzeczywistego wkładu autora
Jak wspomnieliśmy powyżej, sztuczna inteligencja coraz częściej pełni rolę pomocnika technicznego, który pomaga naukowcowi lepiej wyrazić swoje myśli, a nie zastępuje ludzkie myślenie. Na przykład, gdy matematyk używa kalkulatora do obliczeń, nie oznacza to, że nie jest autorem badania.
Podobnie, użycie modeli językowych do edycji lub formatowania tekstu nie umniejsza wkładu autora w pracę. Jednak detektory nie potrafią tego ocenić. Nie rozróżniają, czy autor sam opracował metodologię, przeprowadził eksperyment, przeanalizował dane i wyciągnął wnioski (wykorzystując sztuczną inteligencję wyłącznie do technicznego ulepszenia tekstu), czy po prostu wygenerował cały artykuł automatycznie. Takie ograniczenie prowadzi do błędnych wniosków dotyczących jakości i oryginalności pracy naukowej.
Wada 4: Powodowanie poważnych problemów etycznych w środowisku akademickim
Kiedy wykrywacze błędnie identyfikują prace naukowe jako stworzone przez sztuczną inteligencję, powoduje to szereg konfliktów etycznych. Autorzy mogą zostać niesprawiedliwie oskarżeni o naruszenie uczciwości akademickiej, mimo że w rzeczywistości uczciwie pracowali nad swoimi badaniami. Podważa to zaufanie między naukowcami a redakcjami czasopism, a także może zaszkodzić reputacji naukowej badaczy.
Szczególnie narażeni są młodzi naukowcy lub osoby publikujące w języku obcym, ponieważ ich teksty częściej budzą podejrzenia ze względu na mniej naturalny język lub próby poprawienia stylu za pomocą technologii. Ponadto fałszywe oskarżenia mogą prowadzić do odrzucenia wysokiej jakości badań, opóźnień w publikacjach i utraty możliwości rozwoju kariery. Określenie prawdziwego autorstwa wymaga znacznie głębszej analizy niż automatyczna kontrola za pomocą programu.
Przykłady błędów w działaniu wykrywaczy AI
Aby zrozumieć, jak niestabilność wykrywaczy AI przejawia się w praktyce, rozważmy trzy rzeczywiste przypadki.
Przypadek praktyczny 1: Pogorszenie wyników po poprawkach
W tym przypadku autorzy artykułu naukowego stanęli w obliczu sytuacji, która wyraźnie pokazuje zawodność wykrywaczy AI. Wstępna kontrola artykułu przez czasopismo wykazała 28% prawdopodobieństwa wykorzystania sztucznej inteligencji. Redakcja poprosiła o obniżenie tego wskaźnika do 20% i przedstawiła szczegółowy raport, w którym konkretne fragmenty tekstu zostały oznaczone jako „AI-like”.
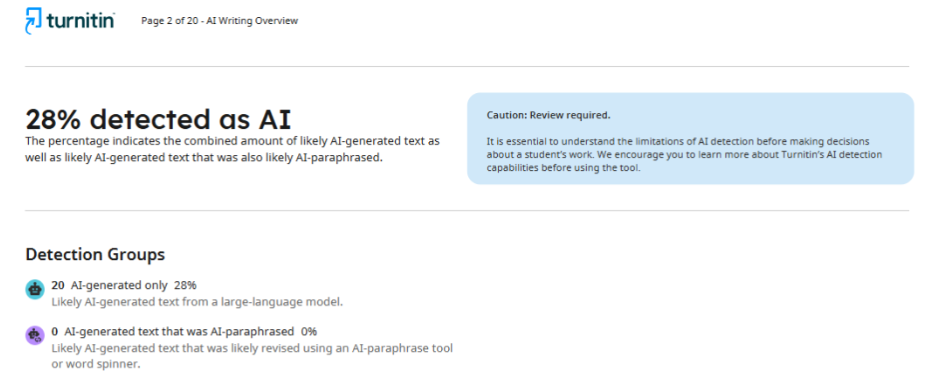
Autorzy przepisali wyłącznie te fragmenty, które detektor uznał za problematyczne, nie zmieniając pozostałej części tekstu. Jednak po ponownej kontroli ten sam czasopismo przedstawiło raport z wynikiem 89%. W rzeczywistości wskaźnik wzrósł ponad trzykrotnie zamiast oczekiwanego spadku.
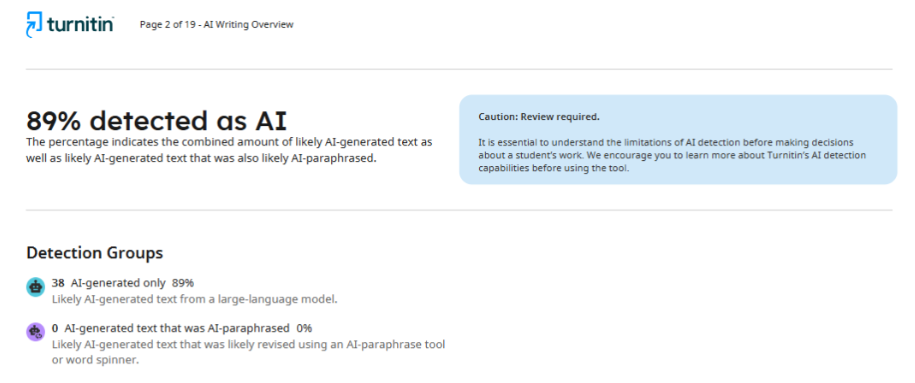
Sytuacja ta ujawnia jeden z kluczowych problemów wykrywaczy AI: nie mają one stabilnych kryteriów oceny i dają nieprzewidywalne wyniki nawet po poprawkach.
Przypadek praktyczny 2: Różne wyniki dla jednego tekstu
Jeszcze bardziej wymowny jest przypadek, w którym ta sama wersja artykułu, sprawdzona przez ten sam system, ale w różnych czasopismach, uzyskała znacznie różne wyniki. W pierwszym wydawnictwie naukowym system wykazał 49% wykorzystania sztucznej inteligencji.
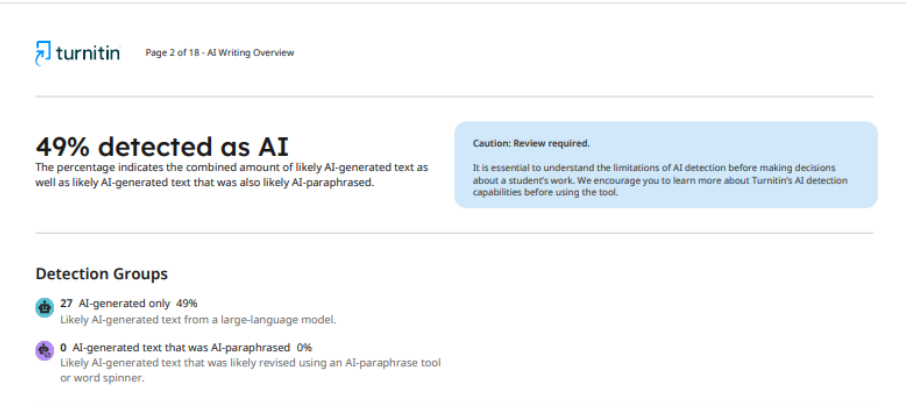
Jeśli chodzi o drugi czasopismo, po sprawdzeniu artykułu przekazało autorowi raport, w którym wskazano 62% wykorzystania sztucznej inteligencji. Taka niespójność wyników wskazuje, że detektory nie są w stanie zapewnić stabilnej i dokładnej oceny, a ich zdolność do określenia, czy podczas pisania wykorzystano technologie sztucznej inteligencji, pozostaje kwestią sporną.
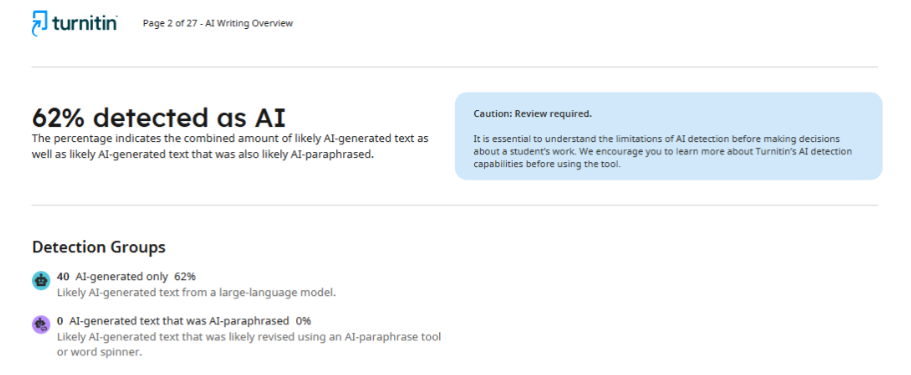
Przypadek praktyczny 3: Różnica w wynikach różnych programów
Warto zauważyć, że nie istnieje uniwersalny program, z którego korzystałyby wszystkie czasopisma naukowe. Każde wydawnictwo naukowe samodzielnie wybiera narzędzia do sprawdzania artykułów pod kątem śladów sztucznej inteligencji. To właśnie ten aspekt ma istotny wpływ na obiektywność wyników.
Na przykład w tym przypadku do analizy jednego artykułu wykorzystano dwa różne detektory: Turnitin i Pangram. W raporcie dostarczonym przez pierwszą platformę wskazano, że 45% tekstu zostało wygenerowane przez sztuczną inteligencję.
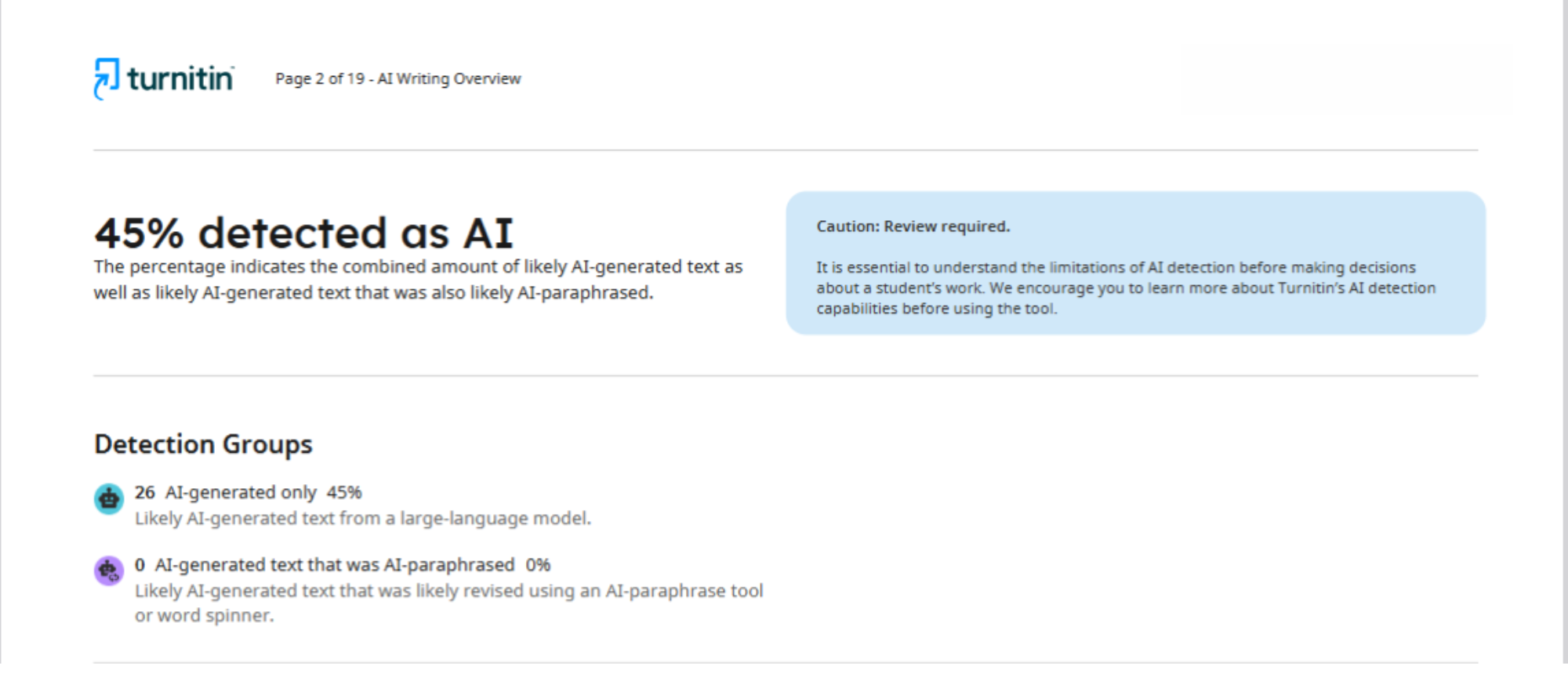
Jeśli chodzi o Pangram, to stwierdził on, że artykuł jest w 75% wynikiem pracy sztucznej inteligencji. Jak widać, różnica między uzyskanymi wynikami jest ogromna.

Sytuacja ta wyraźnie pokazuje, że każde narzędzie do sprawdzania tekstów ma własne algorytmy, kryteria i podejście do rozpoznawania generowanych treści. Brak jednolitych standardów wykrywania oznacza, że los artykułu naukowego może zależeć nie od jego rzeczywistej jakości i oryginalności, ale od tego, jaki program wybrało konkretne czasopismo.
Czy warto ufać narzędziom do sprawdzania obecności sztucznej inteligencji?
Podane przykłady i wyżej wymienione wady wskazują, że współczesne detektory sztucznej inteligencji mają istotne ograniczenia i niedokładności, które podważają ich wiarygodność jako jedynego kryterium oceny. Mogą one dawać nieprzewidywalne wyniki, nie zawsze uwzględniają kontekst wykorzystania technologii i czasami błędnie identyfikują dobrze napisane teksty akademickie jako stworzone przez sztuczną inteligencję. Kiedy ten sam tekst otrzymuje różne oceny w różnych testach, a próby poprawienia zaznaczonych fragmentów prowadzą do nieoczekiwanych rezultatów, staje się oczywiste, że narzędzia te nie osiągnęły jeszcze wymaganego poziomu dokładności.
Dlatego też stosowanie ich jako głównego lub jedynego kryterium przy podejmowaniu decyzji o publikacji jest ryzykowne. Nawet sami twórcy tych systemów zauważają, że ich programy nie są doskonałe i mogą popełniać błędy, a wynik kontroli jest jedynie prawdopodobnym przypuszczeniem dotyczącym pochodzenia tekstu, a nie ostatecznym dowodem.
Przede wszystkim środowisko akademickie powinno opracować przejrzystą politykę dotyczącą etycznego wykorzystania sztucznej inteligencji, kładąc nacisk na ocenę oryginalności treści, metodologii i wkładu naukowego autora. Tylko takie podejście pozwoli zachować uczciwość akademicką, jednocześnie dostosowując się do szybkiego rozwoju współczesnych technologii.


