Штучний інтелект міцно вкорінився в різні сфери діяльності, і наука не є винятком. Чимало вчених активно використовують його в процесі написання наукових робіт. Саме тому перед публікацією наукові журнали ретельно перевіряють статті на наявність слідів ШІ. Втім, чи дійсно такі детектори є ефективними? Чи дають вони стовідсоткову гарантію достовірності результатів? Сьогодні поговоримо про це детальніше.

ШІ-детектори: Чи ефективно вони працюють?
Дотримання принципів академічної доброчесності – це основа наукової діяльності. Тому перед тим, як надіслати статтю на рецензування, наукові журнали перевіряють її на можливі ознаки використання штучного інтелекту. Для цього існують спеціальні інструменти, які аналізують текст та надають звіт щодо унікальності. Однак на практиці такі ШІ-детектори працюють далеко не бездоганно. Навпаки, вони мають чимало недоліків, які можуть суттєво вплинути на об’єктивність результатів. Як саме вони проявляються?
Недолік 1: Хибнопозитивні результати через академічний стиль
Наукові тексти за своєю природою мають схожий стиль написання, оскільки у них використовуються усталені терміни, типові конструкції речень та нейтральний тон. У процесі аналізу детектори шукають саме ці ознаки, зокрема повторювані мовні шаблони, формальний виклад та чітку структуру. Вони є так званими «маркерами», які мають свідчити про те, що автором тексту є не людина, а інструмент на основі штучного інтелекту.
У результаті виникає парадокс: автор, який добре володіє науковим стилем, використовує правильну термінологію та дотримується стандартів, автоматично потрапляє під підозру. Чим краще написана стаття, тим вища ймовірність, що детектор помилково визначить її як текст, створений штучним інтелектом. Як наслідок, він видає хибнопозитивні результати та високий відсоток використання ШІ.
Недолік 2: Нерозуміння того, як насправді автори використовують технології ШІ
У науковій спільноті існує думка, що дослідники використовують технології штучного інтелекту виключно для генерації повного тексту статті. Однак насправді це – упередження, адже сучасні науковці застосовують ШІ як помічника на різних етапах роботи, наприклад, для генерації ідей під час мозкового штурму, для структурування великої кількості даних, для перефразування складних формулювань, для виправлення граматики в текстах іноземною мовою або для покращення читабельності окремих абзаців. Це точкове, усвідомлене використання інструменту, де головні ідеї, методологія та висновки залишаються авторськими.
Але детектори не бачать цієї різниці. Для алгоритму немає значення, чи ви згенерували всю статтю одним запитом, чи використали мовну модель лише для покращення двох речень. Будь-яке використання допоміжних технологій автоматично маркує статтю як «написану штучним інтелектом», що не відповідає дійсності.
Недолік 3: Неможливість оцінити реальний внесок автора
Як ми зазначили вище, ШІ все частіше виступає як технічний помічник, який допомагає науковцю краще висловити власні думки, а не як замінник людського мислення. Наприклад, коли математик використовує калькулятор для обчислень, це не означає, що він не є автором дослідження.
Так само використання мовних моделей для редагування чи форматування тексту не скасовує того, що автор вклав у роботу. Але детектори не вміють це оцінювати. Вони не розрізняють, чи автор сам розробив методологію, провів експеримент, проаналізував дані та зробив висновки (використавши ШІ лише для технічного покращення тексту), чи просто згенерував усю статтю автоматично. Така обмеженість призводить до неправильних висновків про якість та оригінальність наукової роботи.
Недолік 4: Створення серйозних етичних проблем в академічному середовищі
Коли детектори помилково визначають наукові роботи як створені штучним інтелектом, це породжує ланцюг етичних конфліктів. Автори можуть отримати несправедливі звинувачення у порушенні академічної доброчесності, хоча насправді вони чесно працювали над своїм дослідженням. Це підриває довіру між науковцями та редакціями журналів, а також може зашкодити науковій репутації дослідників.
Особливо вразливими стають молоді науковці або ті, хто публікується іноземною мовою, оскільки їхні тексти частіше потрапляють під підозру через менш природну мову або спроби відшліфувати стиль за допомогою технологій. Крім того, помилкові звинувачення можуть призвести до відхилення якісних досліджень, затримки публікацій та втрати можливостей для кар'єрного розвитку. Визначення справжнього авторства вимагає набагато глибшого аналізу, ніж автоматична перевірка програмою.
Приклади помилок у роботі ШІ-детекторів
Для того, щоб зрозуміти, яким чином проявляється нестабільність ШІ-детекторів на практиці, розгляньмо три реальних кейси.
Практичний кейс 1: Погіршення результатів після правок
У цьому випадку автори наукової статті зіткнулися з ситуацією, яка наочно демонструє ненадійність ШІ-детекторів. Первинна перевірка статті журналом показала результат 28% ймовірного використання штучного інтелекту. Редакція попросила знизити цей показник до 20% і надала детальний звіт, у якому конкретні фрагменти тексту були позначені як «AI-like».
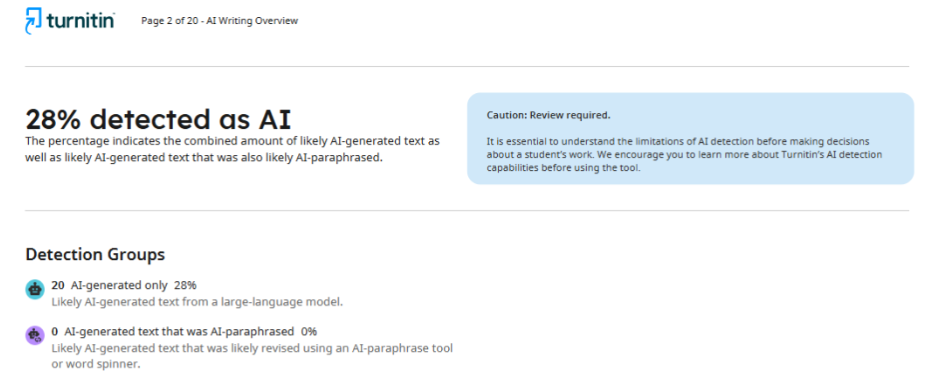
Автори переписали виключно ті фрагменти, які детектор визначив як проблемні, не торкаючись решти тексту. Однак після повторної перевірки той самий журнал надав звіт із результатом 89%. Фактично показник зріс більш ніж утричі замість очікуваного зниження.
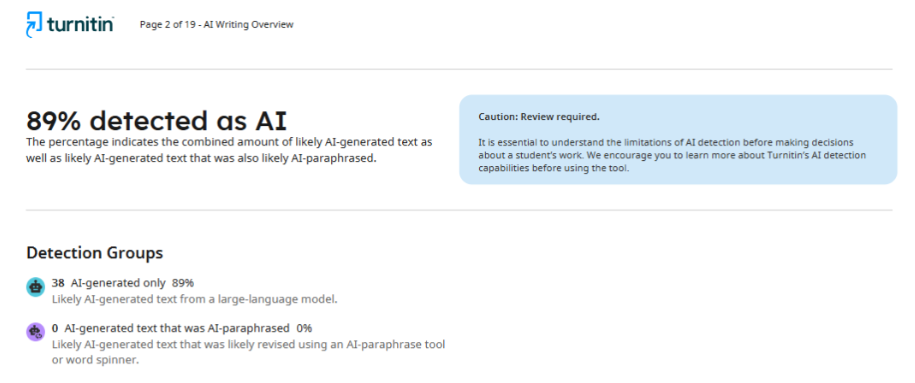
Ця ситуація розкриває одну з ключових проблем ШІ-детекторів: вони не мають стабільних критеріїв оцінки і дають непередбачувані результати навіть після виправлень.
Практичний кейс 2: Різні результати для одного тексту
Ще більш показовим є випадок, коли одна й та сама версія статті, перевірена однією й тією ж системою, але в різних журналах, отримала суттєво різні результати. У першому науковому виданні система показала 49% використання штучного інтелекту.
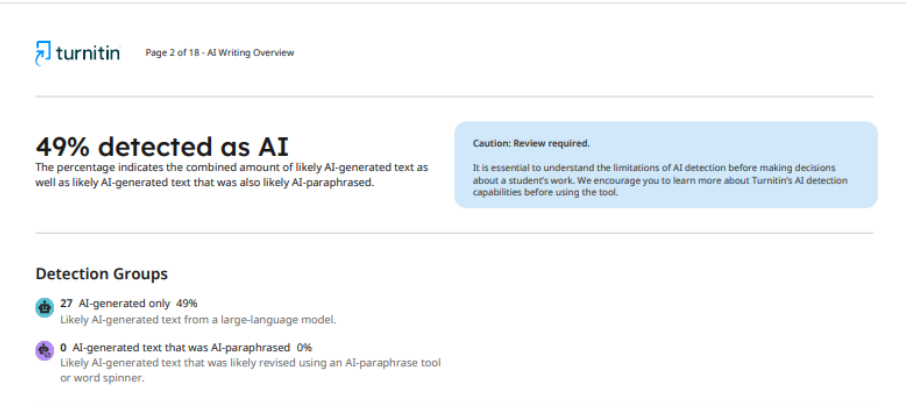
Що стосується другого журналу, то після перевірки статті він надав автору звіт, у якому було вказано 62% використання ШІ. Така непослідовність у результатах вказує на те, що детектори не можуть забезпечити стабільну та точну оцінку, а їхня здатність визначати, чи використовувалися технології штучного інтелекту в процесі написання, залишається під питанням.
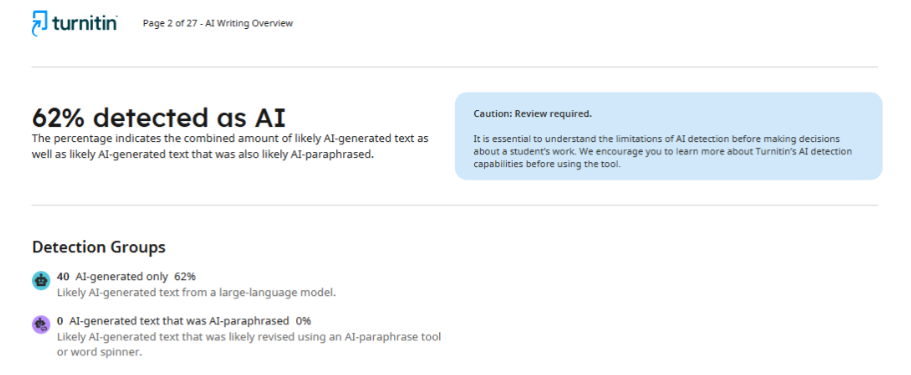
Практичний кейс 3: Різниця в результатах різних програм
Варто зазначити, що не існує універсальної програми, яку використовуватимуть всі наукові журнали. Кожне наукове видання самостійно обирає інструменти для перевірки статей на наявність слідів штучного інтелекту. Саме цей аспект суттєво впливає на об’єктивність результатів.
Наприклад, у цьому випадку для аналізу однієї статті було використано два різних детектори: Turnitin та Pangram. У звіті, який надала перша платформа, зазначено, що текст на 45% згенерований штучним інтелектом.
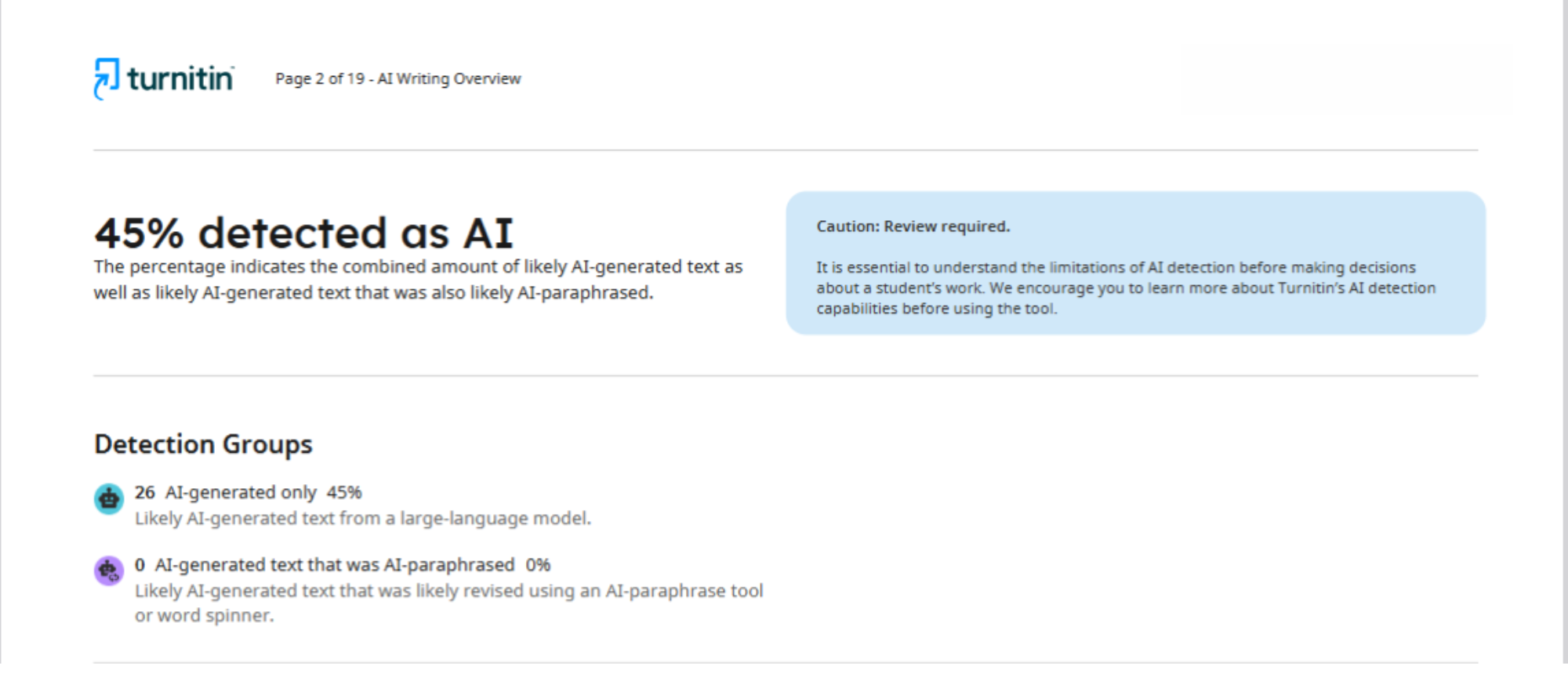
Що стосується Pangram, то він визначив, що стаття є результатом роботи ШІ на 75%. Як бачимо, різниця між отриманими результатами – колосальна.

Ця ситуація наочно демонструє, що кожен інструмент для перевірки текстів має свої власні алгоритми, критерії та підходи до розпізнавання згенерованого контенту. Відсутність єдиних стандартів детекції означає, що доля наукової статті може залежати не від її реальної якості та оригінальності, а від того, яку саме програму обрав конкретний журнал.
Чи варто довіряти інструментам перевірки наявності ШІ?
Наведені приклади та вищезгадані недоліки свідчать про те, що сучасні детектори штучного інтелекту мають суттєві обмеження та неточності, які ставлять під сумнів їхню надійність як єдиного критерію оцінки. Вони можуть давати непередбачувані результати, не завжди враховують контекст використання технологій та іноді помилково ідентифікують якісно написані академічні тексти як створені ШІ. Коли один і той самий текст отримує різні оцінки в різних перевірках, а спроби виправити позначені фрагменти призводять до несподіваних результатів, стає очевидним, що ці інструменти ще не досягли необхідного рівня точності.
Тому використовувати їх як основний або єдиний критерій при прийнятті рішень щодо публікації є ризикованим. Навіть самі розробники цих систем зазначають, що їхні програми не є досконалими і можуть помилятися, а результат перевірки є лише ймовірнісним припущенням щодо походження тексту, а не остаточним доказом.
Насамперед академічна спільнота має розвивати прозорі політики щодо етичного використання ШІ, акцентувати на оцінці змістової оригінальності, методології та наукового внеску автора. Лише такий підхід дозволить зберегти академічну доброчесність, одночасно адаптуючись до стрімкого розвитку сучасних технологій.


